Here is a video [8 mins] to introduce the chapter and including the demonstration of a short example in R.
5.1 Introduction
In this chapter we will focus on applications of generalized linear modelling where the response variable follows a binomial distribution. This can arise when the outcome is binary, that is it can take one of only two possible values, or is the sum of a set of such binary outcomes. These two outcomes record whether some event of interest has occurred or not. In the simplest case, the response variable, \(B\) say, is defined as \[
B =
\begin{cases}
1 & \text{if the event has occurred} \\
0 & \text{if the event has not occurred}
\end{cases}
\tag{5.1}\] and we set \(Pr(B=1)=p\), and hence \(Pr(B=0)=1-p\). This is, of course, the definition of a Bernoulli trial leading to a Bernoulli random variables, \(B\sim \text{Bernoulli}(p)\).
Suppose now that there are \(m\) similar binary outcomes, \(B_i, i=1,\dots,m\) with \(Pr(B_i=1)=p\), and that the total number of times that the event occurred is recorded as the response \(Y\). Assuming that \(m\) is known before the trials start, that \(p\) is fixed and that the individual Bernoulli trials are independent then \(Y\) follows a binomial distribution, \(Y\sim \text{B}(m, p)\) with probability mass function \[
f(y) = {m \choose y} p^y(1-p)^{m-y}.
\tag{5.2}\] Note that the binomial random variable can be thought of as the sum of i.i.d Bernoulli random variables, \(Y= B_1+\cdots + B_m\), if that is helpful.
The Binomial distribution \(\text{B}(m, p)\) is often described in terms of success and failure and a binomial distribution in terms of the number of successes in \(m\) independent trials, where \(p\) is the probability of success in each trial. The term success need not correspond to a favourable outcome; it is merely the language traditionally used in connection with this model. For example, success might correspond to death.
Of course, the special case with \(m=1\) reduces to the Bernoulli distribution. Further, if \(Y_1 \sim \text{B}(m_1,p)\) and independently \(Y_2 \sim \text{B}(m_2,p)\), then \(Y_1+Y_2\) also follows a binomial distribution, \(\text{B}(m_1+m_2,p)\) – note that is only valid when \(p\) is common.
Recall that the binomial can be re-written in the exponential family form of Equation 3.3 with \[
f(y) = \exp \left\{ y\ \mbox{logit } p + m \log (1-p) + \log {m \choose y}\right\},
\] with natural or canonical parameter \(\theta=\text{logit} \ p = \log \left( p(1-p)\right),\) scale parameter \(\phi=1\), \(b(\theta)=m\log(1+e^\theta)\) and \(c(y,\phi)=\log{m\choose y}\) as in Table 3.3.
5.2 The logistic model
Throughout this module we have assumed that a response variable, \(Y\), depends on a set of explanatory variables, \(\mathbf{x} = \{x_1,\dots, x_p\}\). In particular, for binomial counts from \(\text{B}(m,p)\), \(0<p<1\) with mean \(\mu=mp\) we set the link function, \(g(\mu)\), equal to the linear predictor \(\eta = \sum \beta_j x_j\) and hence have \[
g(\mu) = \sum_{j=1}^p \beta_j x_j = \mathbf{x}^T \boldsymbol{\beta}
\] where \(\boldsymbol{\beta} = \{\beta_1,\dots,\beta_p\}\) are the linear predictor parameters. Recall that the canonical logit link Equation 3.14 for the binomial leads to the systematic part of the model \[
\text{logit}(p) = \log \left( \frac{p}{1-p}\right) = \mathbf{x}^T \boldsymbol{\beta}
\tag{5.3}\] but that other links function are possible, such as the probit, Equation 3.15, the complementary log-log, Equation 3.16, and the cauchit Equation 3.17.
This model can alternatively be written \[
Y\ \sim \text{B}(m,p), \quad \text{where }
p=\frac{\exp \{\mathbf{x}^T \boldsymbol{\beta}\}}{1+\exp\{ \mathbf{x}^T \boldsymbol{\beta}\}}
\tag{5.4}\] which makes the dependence of \(Y\) on \(\mathbf{x}\), and \(\boldsymbol{\beta}\), more explicit.
In general, we might want to consider \(n\) independent binomial random variables representing subgroups of the sample with \(Y_1\sim \text{B}(m_1,p_1), \dots Y_n\sim \text{B}(m_n,p_n)\), see Table 5.1 and hence \[
\mathbf{Y}\ \sim \text{B}(\mathbf{m},\mathbf{p}), \quad \text{and }
\mathbf{p}=\frac{\exp \{X \boldsymbol{\beta}\}}{1+\exp\{ X \boldsymbol{\beta}\}},
\] with response \(\mathbf{Y}=\{Y_1,\dots, Y_n\}\), \(\mathbf{m}=\{m_1,\dots, m_n\}\), \(\mathbf{p}=\{p_1,\dots, p_n\}\), \(X\) being the \(n \times p\) design matrix and \(\boldsymbol{\beta} = \{\beta_1,\dots,\beta_p\}\) the linear predictor parameters.
Table 5.1: Linear logistic model
Group 1
Group 2
\(\dots\)
Group \(n\)
Successes
\(Y_1\)
\(Y_2\)
\(\dots\)
\(Y_n\)
Failures
\(m_1-Y_1\)
\(m_2-Y_2\)
\(\dots\)
\(m_n-Y_n\)
Total
\(m_1\)
\(m_2\)
\(\dots\)
\(m_n\)
Then we can write down the log likelihood of \(\boldsymbol{\beta}\) using Equation 4.12 and Equation 5.2 as \[
l(\boldsymbol{\beta}; \mathbf{y})
=
\sum_{i=1}^n
\left\{
y_i \, \log (p_i) + (m_i-y_i) \log (1-p_i) + \log {m_i \choose y_i}
\right\}
\tag{5.5}\] where \[
p_i=\frac{\exp \{\mathbf{x}_i^T \boldsymbol{\beta}\}}{1+\exp\{ \mathbf{x}_i^T \boldsymbol{\beta}\}}.
\] We would then use the principle of maximum likelihood to estimate \(\boldsymbol{\beta}\)\[
\hat{\boldsymbol{\beta}} = \text{arg} \max_{\boldsymbol{\beta}} \,
l(\boldsymbol{\beta}; \mathbf{y}).
\] Then, the fitted probability are given by \[
\hat{p}_i=\frac{\exp \{\mathbf{x}_i^T \hat{\boldsymbol{\beta}}\}}{1+\exp\{ \mathbf{x}_i^T \hat{\boldsymbol{\beta}}\}}
\] and corresponding fitted values \[
\hat y_i = m_i \, \hat{p}_i.
\]
The Pearson residuals for binomial data take the form \[
e^P_i =
\frac{y_i - m_i\hat{p}_i}{\sqrt{m_i \hat{p}_i (1 - \hat{p}_i)}} .
\] From the general result \(\text{Var}(Y_i)=\phi b''(\theta)\) in Proposition 3.1, it can be shown that \(\text{Var}(Y_i)=m_i {p}_i (1 - {p}_i)\). Then, using the estimate of \(p_i\) leads to the denominator above.
For large \(m_i\), the usual Normal approximation to the Binomial means that the Pearson residuals are approximately \(N(0, 1)\) distributed.
It can be shown that the deviance for the fitted model is \[
D =
2 \sum_{i=1}^n \left\{ y_i \log \left( \frac{y_i} {m_i \hat{p}_i} \right) +
(m_i - y_i) \log \left( \frac{m_i - y_i}{m_i (1 - \hat{p}_i)} \right)
\right\},
\tag{5.6}\] which is approximately \(\chi^2_{n-r}\) distributed if the model is correct, where \(r\) is the number of degrees of freedom in the model (that is the number of parameters or columns of the design matrix).
This formula can be shown to be equivalent to \[
D = 2 \sum_{j=1}^2 \sum_{i=1}^n O_{ji} \log
\frac{O_{ji}}{E_{ji}}
\] where \(O_{ji}\) denotes the observed value and \(E_{ji}\) denotes the expected value in cell \((j,i)\) of the \(2 \times n\) table of successes and failures:
Observed and expected frequencies in the linear logistic model
Group 1
Group 2
\(\dots\)
Group \(n\)
Successes, \(j=1\)
\(O_{11}\)
\(O_{12}\)
\(\dots\)
\(O_{1n}\)
\(E_{11}\)
\(E_{12}\)
\(\dots\)
\(E_{1n}\)
Failures, \(j=2\)
\(O_{21}\)
\(O_{22}\)
\(\dots\)
\(O_{2n}\)
\(E_{21}\)
\(E_{22}\)
\(\dots\)
\(E_{2n}\)
Another goodness-of-fit statistic is the Pearson chi-squared statistic: \[
X^2 = \sum_{j=1}^2 \sum_{i=1}^n \frac{(O_{ji} - E_{ji})^2}{E_{ji}}.
\] This is asymptotically equivalent to the deviance Equation 5.6 (proof is by Taylor series expansion; omitted). Thus, asymptotically, \(X^2\) is also approximately \(\chi^2_{n-r}\) distributed. Both approximations can be poor if the expected frequencies are small, but \(X^2\) copes slightly better with this problem. See Dobson, p.136 for more details.
Focus on model choice quiz
Test knowledge recall and comprehension to reinforce ideas of linear and non-linear models. More questions to be added later.
Which of the following is NOT a true statements about modelling?
Which of the following is a true statements about linear regression?
Which of the following is a true statements about logistic regression?
More detail will be added later.
The starting point should always to learn about the background to a data set as this often suggests models to consider, appropriate distributions and any potential problems. Hence saying that it is only the data that maters is inappropriate.
Of course there are many important things to check, but looking at residuals is one of the most important.
Logistic regression assumes that the data follow a binomial distribution.
5.3 Overdispersion
Examination of residuals and deviances may indicate that a model is not an adequate fit to the data. One possible reason is overdispersion. In particular, it is advisable to compare the residual deviance of the proposed model with the corresponding degrees of freedom. If the ratio, deviance divided by degrees of freedom, is substantially greater than 1, then there is evidence for overdispersion – substantially less than 1 indicates under dispersion but that is very rare. Overdispersion can occur for any error distribution where the variance is linked to the mean — e.g. Binomial, Poisson. In the binomial case, overdispersion is called extra-Binomial variation.
Recall that if \(Y_i \sim \text{Bin}(m_i, p_i)\), \(\text{Var}(Y_i) = m_i p_i (1 - p_i)\). Overdispersion occurs if observations which have been modelled by a \(\text{Bin}(m_i, \hat{p}_i)\) distribution have substantially greater variation than \(m_i \hat{p}_i (1 - \hat{p}_i)\). This will lead to a value of \(D\) substantially greater than the expected value of \(n - r\). This can occur if the model is missing appropriate explanatory variables or has the wrong link function, or if the \(Y_i\) are not independent.
One solution is to include an extra parameter \(\tau\) in the model so that \(\text{Var}(Y_i) = \tau \times m_i p_i (1 - p_i)\). For more details, see Section 7.7 of Dobson or Chapter 6 of Collett (1991) Modelling Binary data, Chapman & Hall.
The \(\texttt{glm}\) function in R allows for extra-Binomial variation by setting \(\texttt{family=quasibinomial()}\) with the usual link functions available.
5.4 Odds ratios for 2x2 tables
In the special case of the data forming a \(2 \times 2\) table, then a commonly calculated summary statistic is the odds ratio. This is a measure of association between the presence or absence of some property and an outcome. It represents the odds that an outcome will occur given presence, compared to the odds of the outcome occurring in the absence of that property.
The following \(2 \times 2\) table summarizes the different possibilities.
Success
Failure
Present
\(y_1\)
\(m_1-y_1\)
Absent
\(y_2\)
\(m_2-y_2\)
Similarly, by dividing by the corresponding row total, the probabilities are summaries as follows.
Success
Failure
Present
\(\pi_1\)
\(1-\pi_1\)
Absent
\(\pi_2\)
\(1-\pi_2\)
There are conditional probabilities, for example \(\text{Pr}(\text{Success} | \text{Present})\) etc., and form a stochastic matrix where sum of each row is now 1.
For each row, the odds of success is defined by \[
O_i = \pi_i/(1-\pi_i), \quad i=1,2,
\] and a comparison between these two probabilities is given by the odds ratio\[
\phi = \frac{O_1}{O_2} = \frac{\pi_1(1-\pi_2)}{\pi_2(1-\pi_1)}.
\] If \(\phi=1\) then the property does not affect the odds of success, \(\phi>1\) indicates that the property is associated with higher odds of success, and \(\phi<1\) indicates the property is associated with lower odds of success.
Note that the log-odds, \(\log O_i = \log \left(\pi_i/(1-\pi_i) \right)\), which is the \(\text{logit}(\pi_i),\) and hence is the natural parameter in the regular exponential family form of the binomial distribution.
Finally, an approximate 100(1-\(\alpha\))% confidence interval, \(\left(\phi_{\alpha/2},\phi_{1-\alpha/2}\right)\), for the odds ratio is calculated using the formulas: \[
\phi_{\alpha/2} = \phi \times \exp\left(-z_{1-\alpha/2}\sqrt{\frac{1}{y_1}+\frac{1}{(m_1-y_1)}+\frac{1}{y_2}+\frac{1}{(m_2-y_2)}}\right)
\] and \[
\phi_{1-\alpha/2} = \phi \times \exp\left(+z_{1-\alpha/2}
\sqrt{\frac{1}{y_1}+\frac{1}{(m_1-y_1)}+\frac{1}{y_2}+\frac{1}{(m_2-y_2)}}\right)
\] where \(z_{1-\alpha/2}\) is such that \(\text{Pr}(Z \le z_{1-\alpha/2})=1-\alpha/2\). In particular, for a 95% confidence interval \(z_{1-\alpha/2}=z_{0.975}=1.96\).
If the confidence interval for the odds ratio includes the value 1 then the calculated odds ratio would not be considered statistically significant.
5.5 Application to dose–response experiments
A variable dose of some reagent is administered to each study subject, and the occurrence of a specific response is recorded. This is a dose–response experiment, one of the first uses of regression models for Bernoulli (or Binomial) responses.
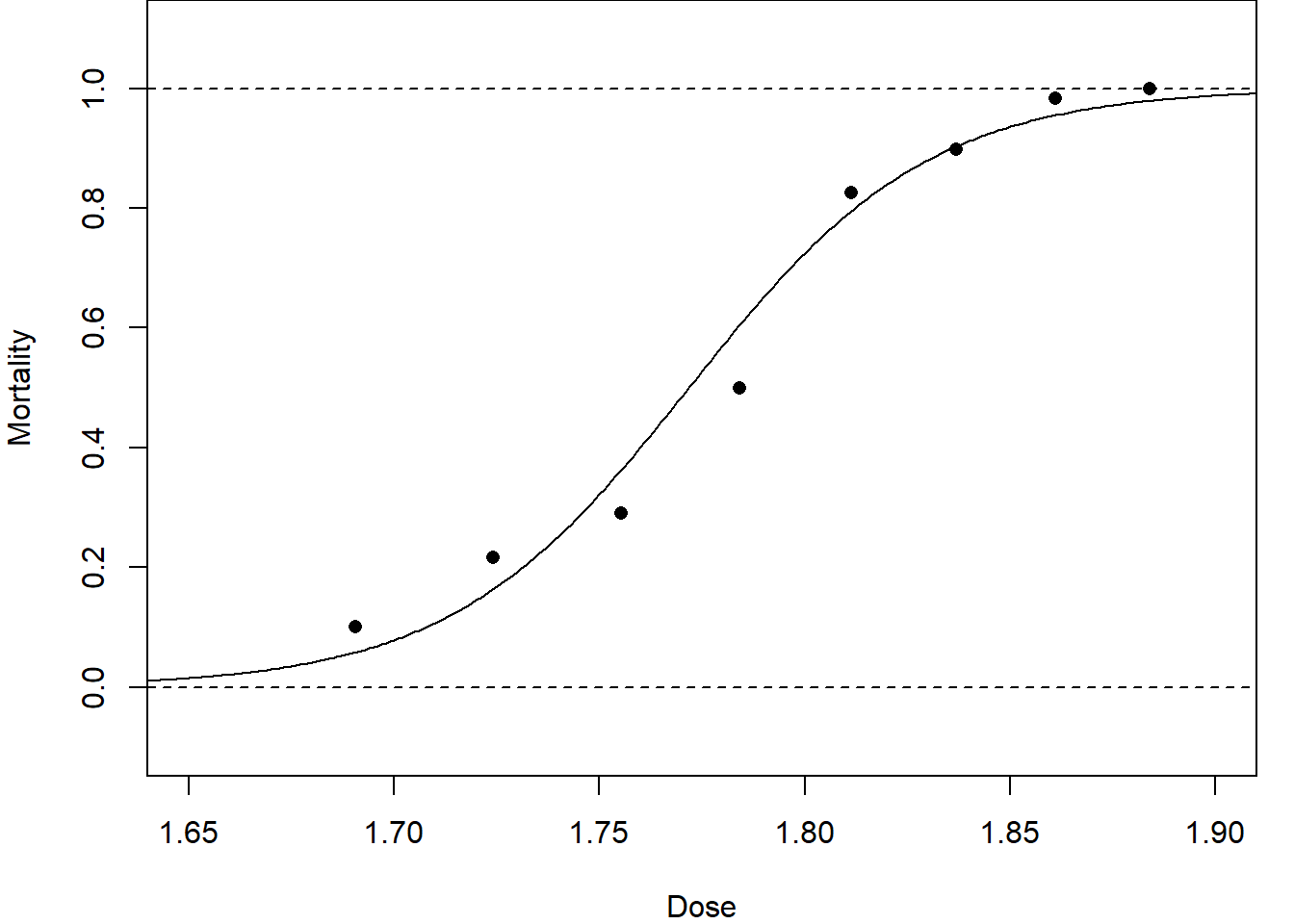
For example, the Table 5.2 (including the information from Table 1.1) gives the number of beetles killed \(y_i\) and the number not killed \((m_i-y_i)\) out of a total number \(m_i\) that were exposed to a dose \(x_i\) of gaseous carbon disulphide, for \(n=8\) dose levels \(i=1,\dots,8\) (Dobson: pp.109 in 1st edn; pp.119 in 2nd edn; pp.127 in 3rd edn). The proportion killed \(p_i = y_i/m_i\) at each dose level \(i\) is also shown in Table 5.2 and plotted in Figure 5.1.
Table 5.2: Numbers of beetles killed by five hours of exposure to 8 different concentrations of gaseous carbon disulphide
Figure 5.1: Beetle mortality rates with fitted dose-response curves.
Now Equation 5.4 motivates modelling the beetle data as \[
Y_i \sim \text{B}(m_i,p_i), \quad \mbox{for } i=1,\dots, n=8
\] where \[
\eta_i = \alpha + \beta x_i
\] and so \[
p_i=\frac{\exp\{\alpha+\beta x_i\}}{(1+\exp\{\alpha+\beta x_i\})}.
\]
To fit this model in R, a matrix with columns containing the numbers killed \(y_i\) and the numbers not killed \(m_i-y_i\) is first calculated
Code
y =cbind(beetle$died, beetle$total-beetle$died)head(y)
or more helpfully a full summary, which contains parameter estimates and deviance values using
Code
summary(glm.fit)
Call:
glm(formula = y ~ dose, family = binomial)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -60.717 5.181 -11.72 <2e-16 ***
dose 34.270 2.912 11.77 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 284.202 on 7 degrees of freedom
Residual deviance: 11.232 on 6 degrees of freedom
AIC: 41.43
Number of Fisher Scoring iterations: 4
or the anova table
Code
anova(glm.fit)
Analysis of Deviance Table
Model: binomial, link: logit
Response: y
Terms added sequentially (first to last)
Df Deviance Resid. Df Resid. Dev
NULL 7 284.202
dose 1 272.97 6 11.232
Clearly, many of the results are repeated in the various R output.
When considering testing model goodness of fit, it is important to distinguish between deviance values which compare a given model with the saturated model and deviance values which compare two competing models. For example, in the Analysis of Deviance Table, the right hand values compare the Null model with the saturated and the model including dose with the saturated. Whereas the left hand value is relevant to the comparison of Null model with the mode including dose.
Summary of results:
From the output, we can first test if the Null model, which contains only a constant term, is a good fit to the data using the hypotheses: \[
H_0: \mbox{Null model is true} \mbox{ against } H_1: \mbox{Null model is false}.
\] From the output, note that the Null deviance is \(D_0=284.202\) and that this model has \(r_0=1\) parameters. Therefore, \(D_0\) follows a \(\chi^2\) distribution with \(n-r_0=8-1=7\) degrees of freedom and hence the p-value is:
Code
pchisq(284.202, 7, lower.tail =FALSE)
[1] 1.425247e-57
This means that we reject \(H_0\) as the observed value of \(D\) is in the upper tail of the \(\chi^2\) distribution.
If we had obtained a non-significant result, then we would stop the analysis and conclude that the Null model is an adequate fit.
Next, consider testing the model which includes the explanatory variable where the the hypotheses are \[
H_0: \mbox{Null model is true} \mbox{ against } H_1: \mbox{Model with dose is true}.
\] From the output, the deviance of the proposed model is \(D_1=11.232\) with \(r_1=2\) parameters. The test statistics is then \(D_0-D_1=284.202-11.232=272.97\) which follows a \(\chi^2\) distribution with \(r_1-r_0=2-1=1\) degrees of freedom. The p-value is then
Code
pchisq(272.97, 1, lower.tail =FALSE)
[1] 2.556369e-61
and we reject \(H_0\) in favour of \(H_1\) and conclude that dose is important.
We can finish the testing by checking if this model is a good fit to the data. That is, \[
H_0: \mbox{The model with dose is true} \mbox{ against } H_1: \mbox{The model with dose is false}
\] The deviance of this is \(D_1=11.232\) with \(r_1=2\) parameters which follows a \(\chi^2\) distribution with \(n-r_1=8-2=6\) degrees of freedom and has p=value
Code
pchisq(11.232, 6, lower.tail =FALSE)
[1] 0.08146544
which means that we accept \(H_0\) at the 5% level and conclude that this model is an adequate fit to the data.
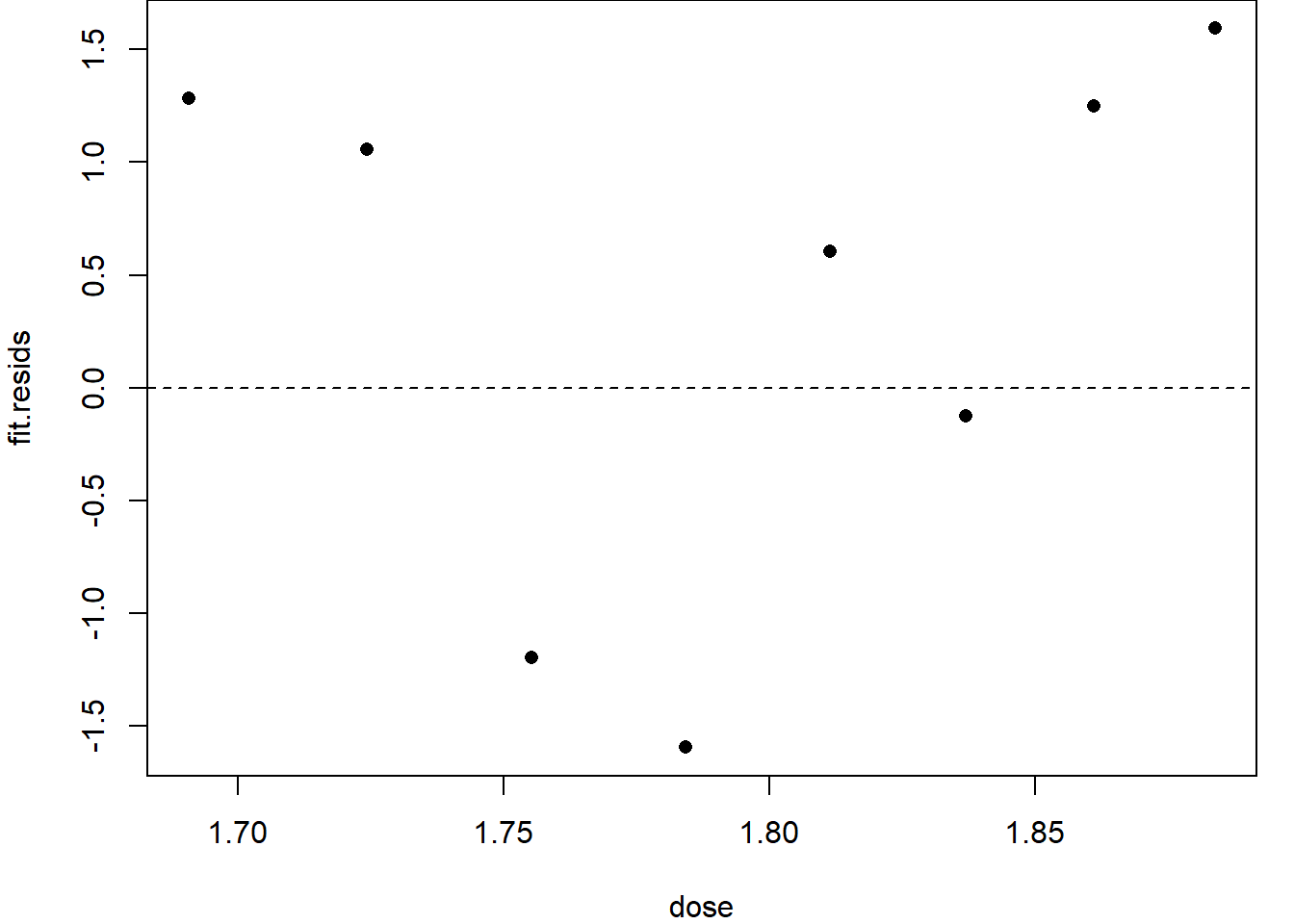
These show a very slight u-shaped pattern and hence it would be work exploring fitting using the other link functions. For this data set, the complementary log-log (cloglog) link has a slightly better fit, see Figure 3.4, but a slight pattern remains.
Before finishing, suppose that we wish to predict, by hand, the probability for dose level \(x_0=1.85\), say, and the expected number of beetles killed when \(m_0=60\) beetles, say, are exposed.
The probability is predicted as \[
\hat p_i = \frac{\exp\{-60.7 + 34.3 x_0\}}{(1+\exp\{ -60.7 + 34.3x_0\})} = 0.936
\] and the expected number of beetles \[
m_0 \, \hat p_i = 56.2
\] Finally, suppose that we wish to find the minimum dose which kills 95% of the beetles, that is \(p_0=0.95\) which requires us to invert the logistic equation.
In general, suppose we wish to find \(x_p\) which corresponds to proportion \(p\) then \[
x_p= \frac{1}{\beta} \left\{ \log\left(\frac{p}{1-p}\right)-\alpha \right\}
\] and hence here \(\hat x_p= 1.856\).
5.6 Exercises
5.1. Which of the following descriptions suggest that a logistic regression should be considered. Justify your answers.
A pharmaceutical company perform clinical trials where volunteers are given varying doses of an experimental drug to study the chances of potential negative side effects. From historical data 4 previous volunteers out of a total of 120 have had negative side effects.
A credit card company monitors sales to identify fraudulent transactions. On the previous five days, 26, 20, 18, 19 and 21 regular transactions occurred before the first fraudulent transaction was identified.
A national internet service provider monitors the frequency of helpline phone calls regarding internet failures. From records, there are an average of 0.27 calls per day.
The University Student Education Services monitor the success of registered students every year. In particular, they record whether students pass their examinations, or not, and what application score they were given when they applied for a place at University.
For each, consider what is response, is it binomial and what is the explanatory variable. In cases which are not binomial, suggest an alternative distribution.
5.2. For each of the situation produce appropriate graphs within RStudio. Describe the type of relationship, if any, shown in the plots. Is a linear, a logistic, or some other model appropriate? If linear or logistic, go ahead with model fitting and perform a residual analysis. Do you think that prediction from the model would be reliable? Justify each step of your analysis.
A UK loan company requires a detailed questionnaire to be completed for any loan application including such information as income, regular expenditure, previous loan details and other information from data analytics and consumer credit reporting companies. All the information is combined into a single credit score from 0 to 1000. A large sample of credit applicants were contacted by an independent market research company to discover the outcome of their application. The data file loans.csv gives the number of successful application, number declined and the credit scores.
A small estate agent company is interested in studying the changes in sales of houses due to targeted advertising campaigns and in particular to determine if additional spending is worthwhile. The company record the weekly sales before each advertising campaign and then again for one week a full month later, along with the cost of each campaign. The datafile advertising.csv contains the advertising budget values in pounds and corresponding changes in sale, also in pounds.
The yield of arable crops is sensitive to the nutrient levels in the soil. A key fertilizer used to boost production is the mineral phosphorus which is applied as phosphorus pentoxide, \(P_2O_5\). At a wheat large farm, various amounts from 0 kg/ha to 80 kg/ha were applied to investigate the effect on wheat yield, in kg/ha. Use the data in file wheat.csv to investigate this situation.
Cardiac troponin (cTn) is a human protein which is commonly measured in the diagnosis of heart attacks. A small sample of blood is taken from patients suspected of having heart attacks and the level of cardiac troponin is recorded The cardiac troponin levels, in ng/mL, of 100 patients arriving at a hospital Accident & Emergency department with significant chest discomfort along with the later confirmed diagnosis (0=No and 1=Yes).
For each, consider what is response, is it binomial and what is the explanatory variable. If the plot reveals a relationship which is either linear or logistic, then follow the appropriate steps previously discussed – check the code blocks in various examples. For the residual analysis, plot a graph of residuals against fitted values and check to a lack of pattern. For the linear cases, also consider the assumption of normality. For example using a histogram.
5.3 In the beetle example, use the fitted logistic regression model, Equation 5.7, to predict what dose of gaseous carbon disulphide would kill 90% of beetles. Then, fit alternative link functions to the data and plot the results. Do you think that the choice of link function makes a difference to your conclusions? Justify your answer.
For the prediction, rearrange the usual expression for p in terms of x and the model parameters to give an expression for x. To fit alternative link functions, just change the argument in the family option.
5.4 (Based on Dobson & Barnett, pp 144–145). Suppose there are 2 groups of people: the first group is exposed to some pollutant and the second group is not. In a prospective study, each group is followed for several years and categorized according to the presence or absence of some disease. Let \(\pi_i\) denote the probability that a person in group \(i\) contracts the disease, \(i=1,2.\) The following \(2 \times 2\) table summarizes the different possibilities.
Diseased
Not diseased
Exposed
\(\pi_1\)
\(1-\pi_1\)
Not exposed
\(\pi_2\)
\(1-\pi_2\)
Note that the sum of each row is 1. For each \(i=1,2\), the odds of contracting the disease is defined by \[
O_i = \pi_i/(1-\pi_i),
\] and a comparison between these two probabilities is given by the odds ratio\[
\phi = \frac{O_1}{O_2} = \frac{\pi_1(1-\pi_2)}{\pi_2(1-\pi_1)}.
\]
Show that \(\phi=1\) if and only if there is no difference between the control and exposed groups. What does it mean if \(\phi > 1\)?
Consider now \(m\) tables where each is of this form, with probabilities \(\pi_{ij}\) represented by a logistic model \[
\text{logit}(\pi_{ij}) = \alpha_i + \beta_i x_j, \ i=1,2,\
j=1,\ldots,m,
\] where \(x_j\) is some specified quantitative explanatory variable. Interpret the parameters \(\alpha_i\) and \(\beta_j\), and give their effect on the log odds ratio \(\log \phi_j\), say, for each table. Show that \(\log \phi_j\) is constant across the \(m\) tables if \(\beta_1 = \beta_2\).
Give a practical example where such a model might be appropriate.
How would you express this model in the R computer language?
In (a), one way is easy. For the other way, rearrange the odds ration and consider the ratios of the event occurring and the ratio that the events not occurring. These are only equal if the probabilities are the same. In (b), note that the log odds ratio is exactly the logistic transform. Substitute in and simplify. An example should be easy, and check ealier for the R command.
5.5. Consider again the beetle example, but suppose that rather than the actual dose concentration had been measured, instead only whether a Low dose or High dose was used recorded. This would lead to the following table:
Died
Not died
Total
Low dose
65
172
237
High dose
226
18
244
What are the respective probability of death values in the two dose groups? The relative risk is defined as the ratio of these two values. Calculate the risk of death due to High dose exposure relative to Low dose for this example. How could this value be used to measure the association between dose and death?
What are the respective odds of death in each of the two groups? Calculate the odds ratio, defined as the ratio of these two values. How could this value be used to interpret the data?
If there is no difference then the relative risk should be 1 and a value substantially different indicates an association. The odds and the odds ratio have a similar interpretation. All measures are do the same thing, but each is standard in particular application areas.